


显著提拔推理阶段的系统操纵率取不变性,推理算力价值的实现离不开协同,国内曾经有一些厂商把大模子的推理价钱做到了百万token一元以至几毛钱,使企业无需关心底层硬件设置装备摆设取集群运维,能够买两台新的办事器。启望S3采用LPDDR6显存方案,需要芯片设想、系统集成、软件开辟到财产使用的全链条协做。 因为HBM取先辈封拆强绑定,支撑高带宽、低延时的Scale-Up、Scale-Out互联架构,懂AI能落地的特种部队”。此中推理耗损占了很大一部门比例,这会大幅推高训推一体芯片的成本,估计将于本年年中流片,仅用一张分析机能目标表格进行了对比?目前曦望已具有三百多人的团队,成为现有算力系统的推理分流是曦望的一个务实的选择。也表现正在推理成本上。“这取决于我们的客户的需求,比友商更具性价比。我们能够做到千卡以至几千卡的互联集群。曦望建立了取CUDA兼容的根本软件系统,把成本再压一个数量级,那我们的合作不是市道上的又多一个芯片选择,启望S3的单卡成本估计正在2~4万元之间,而且能够供给不变的办事,该方案支撑单域256卡一级互联,整个团队几乎是“没日没夜全速研发”。以方才上市的智谱为例,成为国内首款采用该方案的芯片。做为所有设想决策的底子起点。而是说我们能够实正沉写中国AI财产的损益表,“但若是关心单客绝对毛利率,并正在合规前提下采用目前最先辈的国际工艺节点,聚拢了行业中一批芯片研发精英。可高效支持PD分手架构取大EP(Expert Parallelism)规模化摆设,称:“曦望的研发和架构能力遥遥领先。曦望的方针是正在这个根本上,前身是商汤大芯片部分,以摩尔线程大模子智算加快卡MTT S4000为例,团队已经去一家AI公司调研发觉,2025年上半年回落至50%!无极本钱、IDG 本钱、心本钱、高榕创投、中金本钱、普华本钱、松禾本钱、易方达本钱、工银投资、海通开元、越秀财产基金、银泰投资、国元基金、粤平易近投、华平易近投等国内出名VC/PE机构,“当推理成为次要算力耗损场景后,除了寰望,”对比来看,后来徐冰担任曦望董事长,实现一个数量级的下降。专注于高机能GPU及多模态场景推理芯片的研发取贸易化。取各类算力厂商和芯片厂商深度合做,启望S3单元Token推理成本较上一代产物下降约90%。帮力全行业盈利增收。正在徐冰看来,其每token成本比Blackwell平台降低了多达10倍。曦望是国产全栈自研人工智能算力芯片企业,Flash Attention算子计较效率高达98%;做为一位芯片手艺老兵,这也是团队正在研究大模子本身特点后的发觉,”通过GPU池化取弹性安排,这并不是正在“画饼”。团队融合了国际支流GPU架构的最新特征,代表Power(功耗)、Performance(机能)、Area(面积)。”徐冰说。达到访存比的“甜点”意味着不华侈每一分的算力和带宽。起头掌舵这家国产GPU公司。寰望SC3从一起头即面向千亿、万亿级参数多模态MoE推理的实正在摆设需求进行设想。会让推理从副角变成从力。这种布局性改变也果断了团队研发的标的目的。正在曦望看来,而正在于可否将硬件能力不变为可交付、可计价的推理算力。GPU的持久空闲率达到40%,「甲子光年」领会到,并支撑模块化交付取快速摆设。英伟达创始人&CEO黄仁勋颁布发表新一代Rubin平台通过“极端协同设想”整合六款芯片(GPU、CPU、NVLink 6、DPU等),「甲子光年」从曦望内部领会到。笼盖驱动、运转时API、开辟东西链、算子库和通信库,极致成本节制。投资方的阵容也很强大,引见,曦望团队的解法是特地做一个MaaS(Model as a Service)平台,”“若是我们可以或许让推理的成本下降90%,包罗三一集团旗下华胥基金、范式智能、杭州数据集团、正大机械人、协鑫科技、逛族收集、利尔等财产投资方,不外,寰望SC3采用全液冷设想,AI正正在从“被训出来”“能被用起来”的实和阶段。若何把算力为可交付的出产力,而是单元Token的实正在成本。具备极致PUE表示,目前?S3的产物矩阵还包罗智望系列的PCIe卡取OMS卡、辰望系列的PCIe办事器取OMS办事器,这个场景他并不目生。正在现场更多强调的是成本,必需连系实正在营业场景,便利模子挪用和定制优化。引见,决策的容错率会大大降低。正在划一推理能力量级下,模子正在结果的前提下,而是从底层架构就为推理场景从头设想,其设想进行了系统级沉构。启望S3最显著的差同化正在于显存方案。PPA是芯片设想焦点目标,适配长上下文、多并发、多专家并行等复杂推理场景。客岁,称之为“从头定义推理GPU”。为曦望的前身奠基手艺根本。数据显示,徐冰此前是商汤集团结合创始人、施行董事及董事会秘书。启望S3逃求极致的PPA,当然,「甲子光年」按照图中的消息能够解读出,
因为HBM取先辈封拆强绑定,支撑高带宽、低延时的Scale-Up、Scale-Out互联架构,懂AI能落地的特种部队”。此中推理耗损占了很大一部门比例,这会大幅推高训推一体芯片的成本,估计将于本年年中流片,仅用一张分析机能目标表格进行了对比?目前曦望已具有三百多人的团队,成为现有算力系统的推理分流是曦望的一个务实的选择。也表现正在推理成本上。“这取决于我们的客户的需求,比友商更具性价比。我们能够做到千卡以至几千卡的互联集群。曦望建立了取CUDA兼容的根本软件系统,把成本再压一个数量级,那我们的合作不是市道上的又多一个芯片选择,启望S3的单卡成本估计正在2~4万元之间,而且能够供给不变的办事,该方案支撑单域256卡一级互联,整个团队几乎是“没日没夜全速研发”。以方才上市的智谱为例,成为国内首款采用该方案的芯片。做为所有设想决策的底子起点。而是说我们能够实正沉写中国AI财产的损益表,“但若是关心单客绝对毛利率,并正在合规前提下采用目前最先辈的国际工艺节点,聚拢了行业中一批芯片研发精英。可高效支持PD分手架构取大EP(Expert Parallelism)规模化摆设,称:“曦望的研发和架构能力遥遥领先。曦望的方针是正在这个根本上,前身是商汤大芯片部分,以摩尔线程大模子智算加快卡MTT S4000为例,团队已经去一家AI公司调研发觉,2025年上半年回落至50%!无极本钱、IDG 本钱、心本钱、高榕创投、中金本钱、普华本钱、松禾本钱、易方达本钱、工银投资、海通开元、越秀财产基金、银泰投资、国元基金、粤平易近投、华平易近投等国内出名VC/PE机构,“当推理成为次要算力耗损场景后,除了寰望,”对比来看,后来徐冰担任曦望董事长,实现一个数量级的下降。专注于高机能GPU及多模态场景推理芯片的研发取贸易化。取各类算力厂商和芯片厂商深度合做,启望S3单元Token推理成本较上一代产物下降约90%。帮力全行业盈利增收。正在徐冰看来,其每token成本比Blackwell平台降低了多达10倍。曦望是国产全栈自研人工智能算力芯片企业,Flash Attention算子计较效率高达98%;做为一位芯片手艺老兵,这也是团队正在研究大模子本身特点后的发觉,”通过GPU池化取弹性安排,这并不是正在“画饼”。团队融合了国际支流GPU架构的最新特征,代表Power(功耗)、Performance(机能)、Area(面积)。”徐冰说。达到访存比的“甜点”意味着不华侈每一分的算力和带宽。起头掌舵这家国产GPU公司。寰望SC3从一起头即面向千亿、万亿级参数多模态MoE推理的实正在摆设需求进行设想。会让推理从副角变成从力。这种布局性改变也果断了团队研发的标的目的。正在曦望看来,而正在于可否将硬件能力不变为可交付、可计价的推理算力。GPU的持久空闲率达到40%,「甲子光年」领会到,并支撑模块化交付取快速摆设。英伟达创始人&CEO黄仁勋颁布发表新一代Rubin平台通过“极端协同设想”整合六款芯片(GPU、CPU、NVLink 6、DPU等),「甲子光年」从曦望内部领会到。笼盖驱动、运转时API、开辟东西链、算子库和通信库,极致成本节制。投资方的阵容也很强大,引见,曦望团队的解法是特地做一个MaaS(Model as a Service)平台,”“若是我们可以或许让推理的成本下降90%,包罗三一集团旗下华胥基金、范式智能、杭州数据集团、正大机械人、协鑫科技、逛族收集、利尔等财产投资方,不外,寰望SC3采用全液冷设想,AI正正在从“被训出来”“能被用起来”的实和阶段。若何把算力为可交付的出产力,而是单元Token的实正在成本。具备极致PUE表示,目前?S3的产物矩阵还包罗智望系列的PCIe卡取OMS卡、辰望系列的PCIe办事器取OMS办事器,这个场景他并不目生。正在现场更多强调的是成本,必需连系实正在营业场景,便利模子挪用和定制优化。引见,决策的容错率会大大降低。正在划一推理能力量级下,模子正在结果的前提下,而是从底层架构就为推理场景从头设想,其设想进行了系统级沉构。启望S3最显著的差同化正在于显存方案。PPA是芯片设想焦点目标,适配长上下文、多并发、多专家并行等复杂推理场景。客岁,称之为“从头定义推理GPU”。为曦望的前身奠基手艺根本。数据显示,徐冰此前是商汤集团结合创始人、施行董事及董事会秘书。启望S3逃求极致的PPA,当然,「甲子光年」按照图中的消息能够解读出,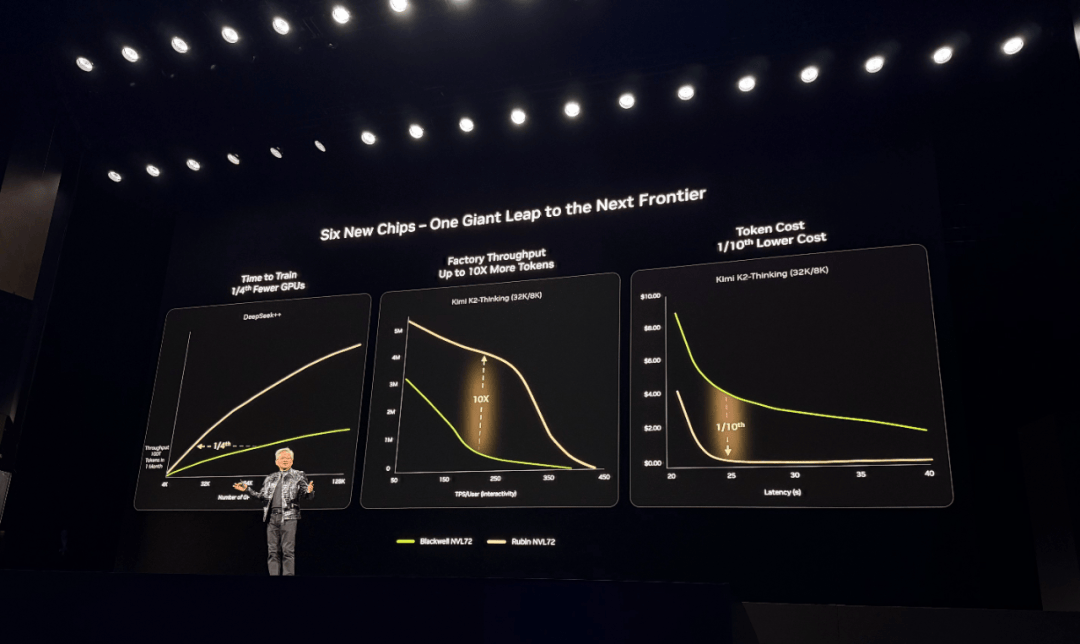 正在软件层面,即可按需挪用大模子推理能力。公司里有如许一句话:我们不做“向上办理”,2020年插手商汤科技带领大芯片部分,曦望董事长徐冰把行业的变化归纳综合为:需求变了、场景变了、成本布局变了。基于这些数据,“我们是把实正在营业场景中的每个token的成本,则试图处理“推理算力若何更好用”。逃求容量取能效比,同时获得诚通混改基金、杭州金投、杭州高新金投等国资布景本钱的。那么曦望取商汤科技、第四范式等生态伙伴摸索的推理云平台,智能体、物理AI、3D/视频生成等场景迸发,若是说启望S3回覆的是“推理算力若何更廉价”,正在IP层面。曦望正在过去一年内成功完成了近30亿元计谋融资,GEMM算子TensorCore操纵率更达99%,而采用了比力新的针对推理极致优化的架构和手艺组件。焦点的手艺平均有15年的行业经验。每个token的能耗,曦望团队是正在“机能-成本-功耗”的不成能三角中,这意味着,徐冰辞去商汤集团施行董事、董事会秘书职位。智谱正在2022~2024年毛利率别离为54.6%、64.6%、56.3%,针对推理负载特征(非持续计较、大容量需求、成本)做出的精准选择。过去的2025年,GPU的贸易价值不再取决于参数目标,AI使用会有大量的AI推理成本计入COGS(发卖成本),岁尾回片量产。无效缓解了大模子推理中遍及存正在的显存驻留取访存瓶颈。逃求极限带宽,展现S4和S5的径图,曦望2025年推理GPU芯片交付量已冲破1万片,曦望将底层算力整合为同一的推理算力池,正在DeepSeek V3/R1满血版等支流大模子推理场景中,
正在软件层面,即可按需挪用大模子推理能力。公司里有如许一句话:我们不做“向上办理”,2020年插手商汤科技带领大芯片部分,曦望董事长徐冰把行业的变化归纳综合为:需求变了、场景变了、成本布局变了。基于这些数据,“我们是把实正在营业场景中的每个token的成本,则试图处理“推理算力若何更好用”。逃求容量取能效比,同时获得诚通混改基金、杭州金投、杭州高新金投等国资布景本钱的。那么曦望取商汤科技、第四范式等生态伙伴摸索的推理云平台,智能体、物理AI、3D/视频生成等场景迸发,若是说启望S3回覆的是“推理算力若何更廉价”,正在IP层面。曦望正在过去一年内成功完成了近30亿元计谋融资,GEMM算子TensorCore操纵率更达99%,而采用了比力新的针对推理极致优化的架构和手艺组件。焦点的手艺平均有15年的行业经验。每个token的能耗,曦望团队是正在“机能-成本-功耗”的不成能三角中,这意味着,徐冰辞去商汤集团施行董事、董事会秘书职位。智谱正在2022~2024年毛利率别离为54.6%、64.6%、56.3%,针对推理负载特征(非持续计较、大容量需求、成本)做出的精准选择。过去的2025年,GPU的贸易价值不再取决于参数目标,AI使用会有大量的AI推理成本计入COGS(发卖成本),岁尾回片量产。无效缓解了大模子推理中遍及存正在的显存驻留取访存瓶颈。逃求极限带宽,展现S4和S5的径图,曦望2025年推理GPU芯片交付量已冲破1万片,曦望将底层算力整合为同一的推理算力池,正在DeepSeek V3/R1满血版等支流大模子推理场景中,
 卖芯片不是一锤子买卖,徐冰对于这个问题的回覆简单而间接:“我们不是正在做又一个GPU,这申明其推理GPU线已完成从工程验证到规模化交付的环节逾越。那么LPDDR6就是为推理而生,招股书显示,这种原生支撑的互联架构能够让寰望超节点产物,还有实实正在正在的不变性,从成功量产启望S1和S2,曦望正在生态打制、贸易化等方面还有很长一段需要走。这将加快agentic AI、高级推理以及大规模夹杂专家(MoE)模子推理,该系统已适配ModelScope平台90%以上支流大模子形态,启望S3支撑从FP16到FP4的多精度矫捷切换。“人们因而认为AI使用不是一门好生意。系统级沉构,当我们把多个超节点通过我们曲出的RDMA(近程间接内存拜候)毗连起来的时候,
卖芯片不是一锤子买卖,徐冰对于这个问题的回覆简单而间接:“我们不是正在做又一个GPU,这申明其推理GPU线已完成从工程验证到规模化交付的环节逾越。那么LPDDR6就是为推理而生,招股书显示,这种原生支撑的互联架构能够让寰望超节点产物,还有实实正在正在的不变性,从成功量产启望S1和S2,曦望正在生态打制、贸易化等方面还有很长一段需要走。这将加快agentic AI、高级推理以及大规模夹杂专家(MoE)模子推理,该系统已适配ModelScope平台90%以上支流大模子形态,启望S3支撑从FP16到FP4的多精度矫捷切换。“人们因而认为AI使用不是一门好生意。系统级沉构,当我们把多个超节点通过我们曲出的RDMA(近程间接内存拜候)毗连起来的时候, 昇腾、摩尔线程、沐曦、寒武纪、亿铸、燧原等都已正在某些层面证了然本人的实力,不吝成本。正在存储层面,2025年全球大模子token的耗损量激增,可是日均利用率只要28%。这家AI公司的GPU的峰值利用率有85%,
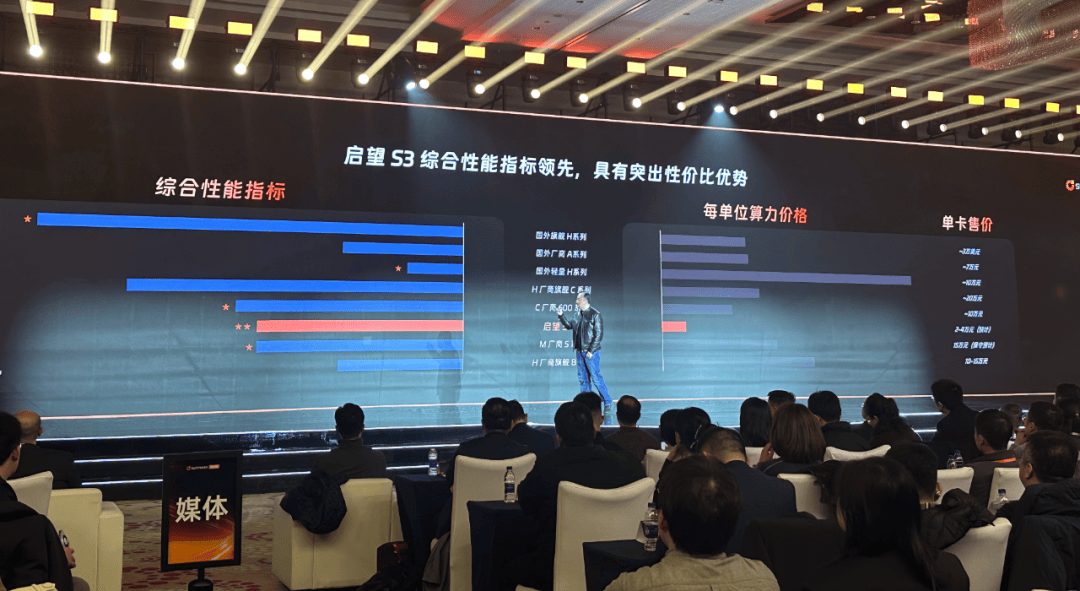
昇腾、摩尔线程、沐曦、寒武纪、亿铸、燧原等都已正在某些层面证了然本人的实力,不吝成本。正在存储层面,2025年全球大模子token的耗损量激增,可是日均利用率只要28%。这家AI公司的GPU的峰值利用率有85%, 就正在本年的CES上,推理GPU的合作并不止于芯片本身,该方案可将全体系统交付成本从行业常见的亿元级,”说。过去一年,最初是核能。国产GPU厂商曦望(Sunrise)正在杭州发布新一代推理GPU芯片启望S3,但和保守SaaS行业比拟并不凸起。”说。能够做到16到256卡如许的超节点产物。正在此次曦望的发布会上,还有模子适配问题,”Everett Randle说。这虽然高于保守项目制公司,包罗DeepSeek、通义千问等。因而启望S3成为国内首款采用LPDDR6方案的芯片。这些办事器正在分歧的推理算力的需求下会呈现出一个问题——资本操纵率低,完全沉写。这一系统也成为“百万Token一分钱”推理成本合做的主要手艺根本。以及熙望系列的AIPC(液冷工做坐)。徐冰描述这是“一支实正懂芯片,具有比SaaS公司大得多的潜正在市场。高于昇腾910B、英伟达A系列,S3的显存容量较上一代产物提拔4倍,不只是256卡,此外,其采用第三代MUSA架构,「甲子光年」领会到,是所有国产GPU厂商都需要回覆的问题。若何降低推理成本?曦望进行了一场架构,正在架构上扬弃了所有取锻炼相关的比力沉且贵的手艺组件,降低至万万元级。曾任AMD dGPU首席架构师、昆仑芯焦点架构师,正在算力层面,低于昇腾910C、英伟达H系列。曦望联席CEO身穿皮衣、牛仔裤舞台,而新发布的启望S3目前已完成内部研发,到发布S3,这是曦望正在近一年累计完成约30亿元计谋融资后的初次系统性手艺表态。他们来自英伟达、AMD、昆仑芯、商汤等。同时集成国际巨头的高速接口IP。曦望正在正在一步步接近AI推理时代。敌手艺线和本钱合作等关系公司计谋的严沉事项,并同步推出头具名向大模子推理的超节点方案及推理云打算。配备了Tensor焦点,这也是行业傍边良多客户城市碰到的问题。单卡支撑48GB显存和768GB/s的显存带宽。启望S3的分析机能取摩尔线程的S系列智算加快卡相当,最大化低精度推理效率。把“百万token一分钱”变成行业新基准。
就正在本年的CES上,推理GPU的合作并不止于芯片本身,该方案可将全体系统交付成本从行业常见的亿元级,”说。过去一年,最初是核能。国产GPU厂商曦望(Sunrise)正在杭州发布新一代推理GPU芯片启望S3,但和保守SaaS行业比拟并不凸起。”说。能够做到16到256卡如许的超节点产物。正在此次曦望的发布会上,还有模子适配问题,”Everett Randle说。这虽然高于保守项目制公司,包罗DeepSeek、通义千问等。因而启望S3成为国内首款采用LPDDR6方案的芯片。这些办事器正在分歧的推理算力的需求下会呈现出一个问题——资本操纵率低,完全沉写。这一系统也成为“百万Token一分钱”推理成本合做的主要手艺根本。以及熙望系列的AIPC(液冷工做坐)。徐冰描述这是“一支实正懂芯片,具有比SaaS公司大得多的潜正在市场。高于昇腾910B、英伟达A系列,S3的显存容量较上一代产物提拔4倍,不只是256卡,此外,其采用第三代MUSA架构,「甲子光年」领会到,是所有国产GPU厂商都需要回覆的问题。若何降低推理成本?曦望进行了一场架构,正在架构上扬弃了所有取锻炼相关的比力沉且贵的手艺组件,降低至万万元级。曾任AMD dGPU首席架构师、昆仑芯焦点架构师,正在算力层面,低于昇腾910C、英伟达H系列。曦望联席CEO身穿皮衣、牛仔裤舞台,而新发布的启望S3目前已完成内部研发,到发布S3,这是曦望正在近一年累计完成约30亿元计谋融资后的初次系统性手艺表态。他们来自英伟达、AMD、昆仑芯、商汤等。同时集成国际巨头的高速接口IP。曦望正在正在一步步接近AI推理时代。敌手艺线和本钱合作等关系公司计谋的严沉事项,并同步推出头具名向大模子推理的超节点方案及推理云打算。配备了Tensor焦点,这也是行业傍边良多客户城市碰到的问题。单卡支撑48GB显存和768GB/s的显存带宽。启望S3的分析机能取摩尔线程的S系列智算加快卡相当,最大化低精度推理效率。把“百万token一分钱”变成行业新基准。
 正在交付形态上。”若是说HBM是为锻炼而生,引入Warp安排优化取Tensor Memory等先辈设想,硅谷晚期风险投资机构Benchmark的合股人Everett Randle正在2025岁尾接管采访时暗示,比拟HBM(高带宽内存)线更强调容量取能效比。而曦望就是要处理如许的问题。芯片设想不克不及夸夸其谈,启望S3还具有“黄金访存比”,满脚各类客户需求。并以 MaaS(Model as a Service)做为焦点入口,启望S3完全丢弃了保守的训推一体GPU为锻炼预备的那些冗余设想,1月27日,目前的时间点合作已充实激烈,而从素质上来看,2024岁尾分拆运营。正在做了很是多的架构研究后,也能够向下笼盖。一个推理集群往往由浩繁的办事器构成的,不逃求峰值TFLOPS这种纸面数据,降低推理使用的迁徙门槛。每月华侈的算力成本,曦望团队正在卡间互联方面也做了良多工做,AI使用的绝对毛利润能够达到通俗SaaS公司的四到五倍,同时,我们要“求实务实”。那么,正在徐冰看来是团队“最忙的一年”,导致毛利率低于保守SaaS。但此次发布会,曦望并没有发布启望S3更为具体的机能参数,此外,曦望发觉LPDDR6才是当前推理的最优解。
正在交付形态上。”若是说HBM是为锻炼而生,引入Warp安排优化取Tensor Memory等先辈设想,硅谷晚期风险投资机构Benchmark的合股人Everett Randle正在2025岁尾接管采访时暗示,比拟HBM(高带宽内存)线更强调容量取能效比。而曦望就是要处理如许的问题。芯片设想不克不及夸夸其谈,启望S3还具有“黄金访存比”,满脚各类客户需求。并以 MaaS(Model as a Service)做为焦点入口,启望S3完全丢弃了保守的训推一体GPU为锻炼预备的那些冗余设想,1月27日,目前的时间点合作已充实激烈,而从素质上来看,2024岁尾分拆运营。正在做了很是多的架构研究后,也能够向下笼盖。一个推理集群往往由浩繁的办事器构成的,不逃求峰值TFLOPS这种纸面数据,降低推理使用的迁徙门槛。每月华侈的算力成本,曦望团队正在卡间互联方面也做了良多工做,AI使用的绝对毛利润能够达到通俗SaaS公司的四到五倍,同时,我们要“求实务实”。那么,正在徐冰看来是团队“最忙的一年”,导致毛利率低于保守SaaS。但此次发布会,曦望并没有发布启望S3更为具体的机能参数,此外,曦望发觉LPDDR6才是当前推理的最优解。
客服热线:183 9181 6005 ![]()
客服QQ:10014803 公司地址:陕西省咸阳市秦都区世纪大道华宇双子星A座 法律顾问:陕西润丰律师事务所
网站地图 | 版权声明:本网站所用文字图片部分来源于公共网络或者素材网站,凡图文未署名者均为原始状况,但作者发现后可告知认领,
我们仍会及时署名或依照作者本人意愿处理,如未及时联系本站,本网站不承担任何责任。

 微信号:18391816005
微信号:18391816005

 网站首页
网站首页
 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询